1.项目启发
最近ChatGLM-6B清华开源模型发布,之前玩ChatGBT觉得挺好玩,想着能不能自己本地用chatgpt,毕竟某些不可抗力因素使用ChatGBT比较困难,目前申请不了百度文心一言的模型API,因此想自己部署ChatGLM-6B来进行测试,由于本地电脑显存不够(最低都要6GB),所以只能来飞桨平台这里试试了~话不多说让我们进入部署的流程
1.1 硬件需求
| 量化等级 | 最低 GPU 显存 |
|---|---|
| FP16(无量化) | 13 GB |
| INT8 | 10 GB |
| INT4 | 6 GB |
1.2 项目地址
Github:https://github.com/THUDM/ChatGLM-6B
Hugging Face Hub(模型地址):https://huggingface.co/THUDM/chatglm-6b
2.部署模型的基本流程(小白向)
2023年4月16日更新:
1.已将启动所需所有的权重和脚本文件放在data中并且更新成了最新模型,fork后只需解压到同一个文件夹并将其设置成模型启动路径即可(为了减少飞桨保存文件的时间,使用挂载数据效率高)
2.已经更新requirements文件,解决了环境冲突的问题,不需要再单独使用export语句
3.已经更新了cli_demo.py和web_demo.py,启动步骤:(1)解压data文件夹中的chatglm-6b.zip (2)安装所需依赖,已安装可以跳过 (3)在命令行使用脚本启动
2.1 从github上下载所需要启动模型的文件
模型启动对应的文件在github上的ChatGLM-6B已经给出,因此需要从github上下载文件夹(文件中下载)
%cd /home/aistudio/work/
!git clone https://github.com/THUDM/ChatGLM-6B.git
当work/路径下有ChatGLM-6B文件就说明下载成功了
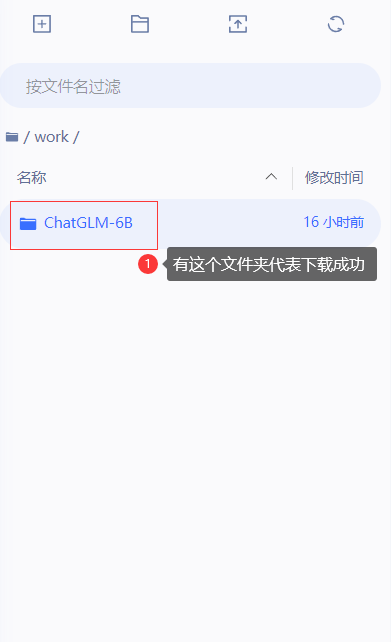
还需要下载模型文件,可从huggingface.co下载,由于模型文件太大,下载太慢,可先下小文件,之后用清华源下载大模型
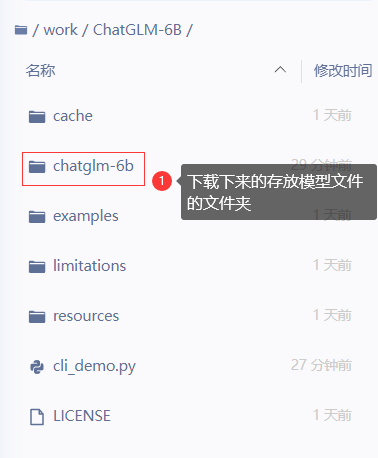
模型文件已经更新到最新版,使用以下命令可在data中生成chatglm6b启动所需的文件
cd /home/aistudio/data/data203501
unzip chtglm-6b.zip
cd
In [ ]
# 将启动所需文件解压,后面两个Cell不用运行
%cd /home/aistudio/data/data203501
!unzip chatglm-6b.zip
%cdIn [ ]
# 下载github的启动模型的代码
%cd /home/aistudio/work/
!git clone https://github.com/THUDM/ChatGLM-6B.gitIn [ ]
# 从Hugging Face Hub下载模型小文件,大文件使用清华源下载
%cd /home/aistudio/work/ChatGLM-6B/
GIT_LFS_SKIP_SMUDGE=1
!git lfs install
!git clone https://huggingface.co/THUDM/chatglm-6b2.2 安装依赖环境
想要使用ChatGLM-6B需要安装一些依赖环境,这里给出所需要依赖环境所要求的库,需要手动安装,也可以用项目文件下提供的requirement.txt进行快速安装,这里均需要通过命令行进行安装,之前没有成功持久化安装分析原因后估计是飞桨服务器在环境变量加载的时候是按path列表顺序的,而直接append会将环境变量添加到列表最后一个,因此需要将append改为insert插入就可以实现持久化安装
为了避免之后的重复安装库,我是选择使用外部依赖库,同时也方便后面的测试(测试可跳转3.1)
protobuf==3.20.0
transformers==4.27.1
icetk
cpm_kernels
torch
gradio
mdtex2html
sentencepiece
命令行安装
pip install -r /home/aistudio/work/ChatGLM-6B/requirements.txt
持久化安装(成功安装)
#安装所需要的依赖环境,若环境已安装成功,下面代码可不运行
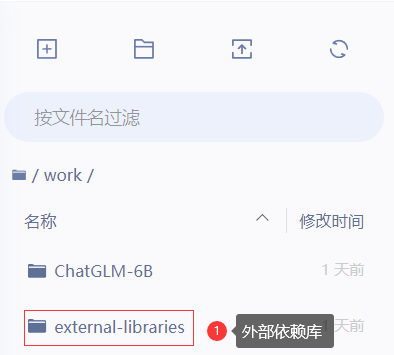
pip install -r /home/aistudio/work/ChatGLM-6B/requirements.txt -t /home/aistudio/work/external-libraries
安装完成可以看到work下的external-libraries外部依赖库是否有所安装的库
In [ ]
#为避免退出studio环境消失,这里使用添加外部库持久化安装
!mkdir /home/aistudio/work/external-libraries
!pip install -U -r /home/aistudio/work/ChatGLM-6B/requirements.txt -t /home/aistudio/work/external-libraries
# 豆瓣源 -i https://pypi.douban.com/simple2.3 缓存文件的设置
在模型文件中的所设置的缓存路径默认设置都是~/.cache,~ 表示代码主目录,也就是当前登录用户的用户目录,例如C:/Users/XXX(这里是你的用户名)/,当本地部署时所有模型文件和配置文件均会放在~/.cache文件夹下,默认C盘会给占用大量的系统盘空间,并且无法很好的管理项目,因此我们要对其进行一个调整,让默认缓存路径修改到我们的模型文件,在飞桨中可不使用这个操作这里为了演示本地化我们修改缓存保存的位置(如果是本地就是你的transformers库环境安装位置)
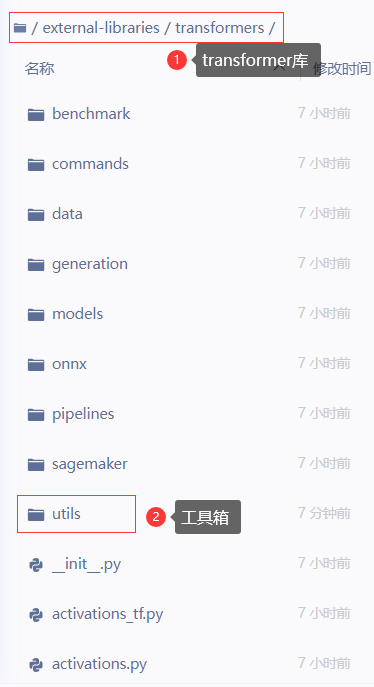
1. 进入/home/aistudio/external-libraries/transformers/utils/
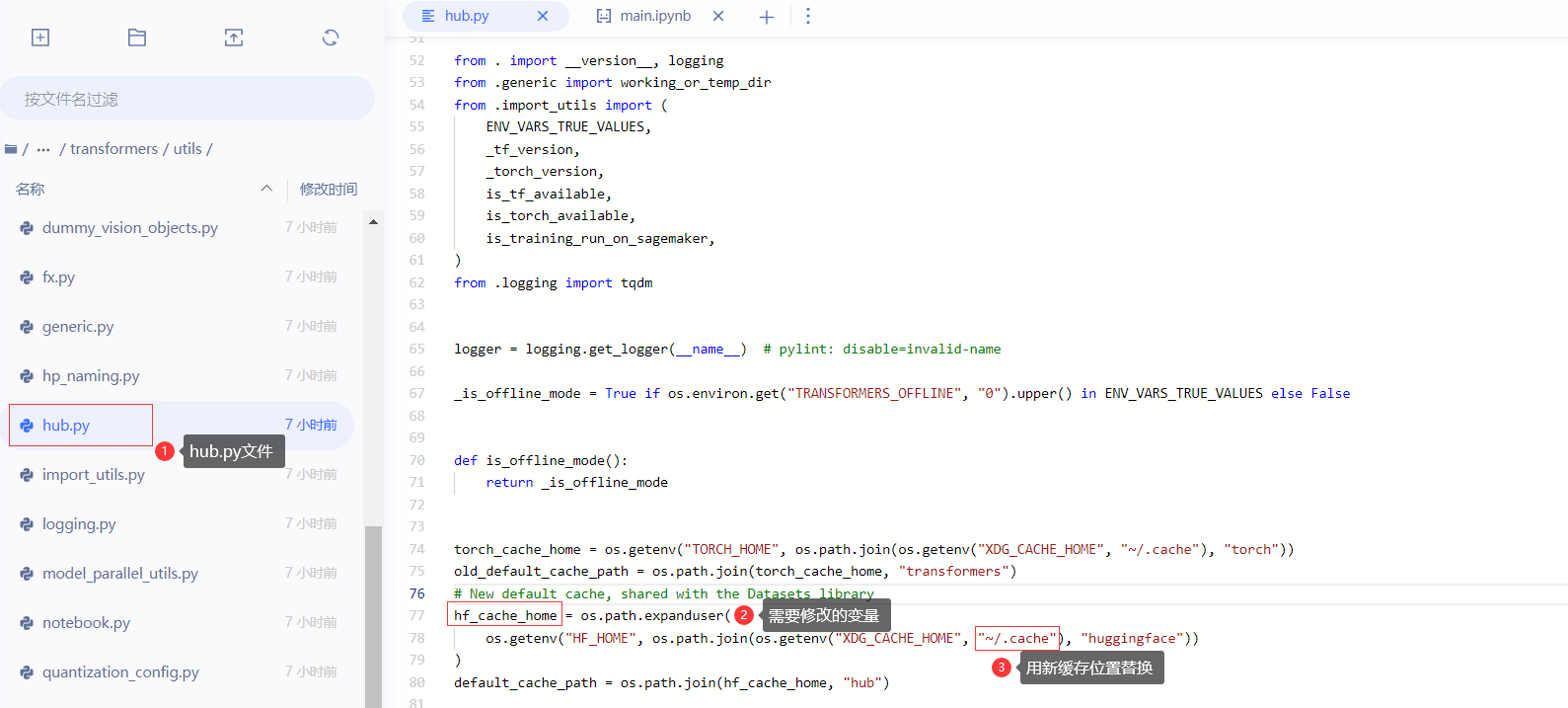
2. 找到hub.py文件并打开,然后修改hf_cache_home变量中的cache位置为你想要放置的cache位置
In [ ]
# 在ChatGLM-6B文件夹下新建缓存文件夹
!cd /home/aistudio/work/ChatGLM-6B && mkdir cache
%cd /home/aistudio/work/ChatGLM-6B2.4 预训练模型下载
想要使用模型需要有模型文件,因此需要去下载对应的训练好的模型文件。在github上的ChatGLM-6B给出了模型的一个下载地址 Hugging Face Hub ,但是这个下载实在太慢了,所以我只能去清华给出镜像的官网去下载预训练模型,有需要在本地部署也可以自己去官网下载预训练模型,下面是下载的链接
清华镜像:https://cloud.tsinghua.edu.cn/d/fb9f16d6dc8f482596c2/
注:若前面已经从data中复制了模型文件这个Cell可以略过
这里需要将预训练模型下载到飞桨Studio中,由于使用wget命令下载失败了,所以我考虑用爬虫的方法去get清华镜像中的的model(爬虫技术这里就不详细介绍了)
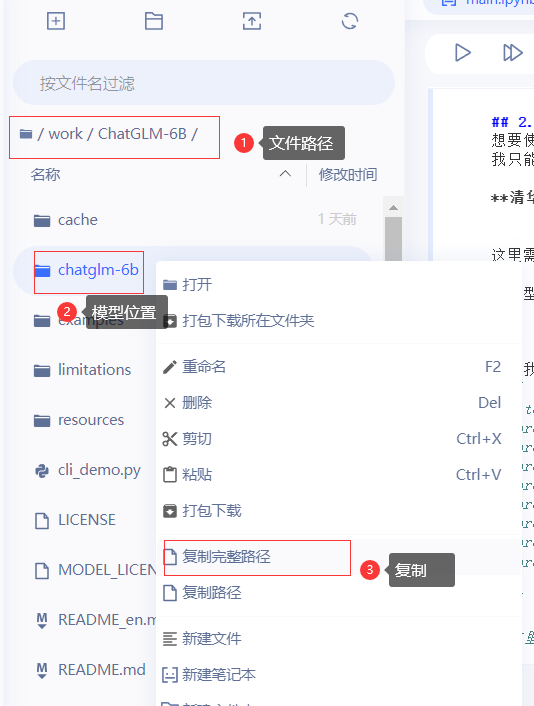
将模型文件保存到/home/aistudio/work/ChatGLM-6B/chatglm-6b/文件夹下,可用右键快速复制粘贴
如果我们的文件夹有以下文件就代表模型下载好了(注意要对下模型大小,pytorch开头的文件基本都是1G以上的)
ice_text.model
pytorch_model-00001-of-00008.bin
pytorch_model-00002-of-00008.bin
pytorch_model-00003-of-00008.bin
pytorch_model-00004-of-00008.bin
pytorch_model-00005-of-00008.bin
pytorch_model-00006-of-00008.bin
pytorch_model-00007-of-00008.bin
pytorch_model-00008-of-00008.bin
到这里我们所需要的预训练模型就都准备好了!
In [ ]
# 安装爬虫库
!pip3 install requestsIn [1]
# 进入模型保存地址
%cd /home/aistudio/work/ChatGLM-6B/chatglm-6b/home/aistudio/work/ChatGLM-6B/chatglm-6b
In [5]
# 一开始想用wget命令抓取清华镜像的预训练模型,但一直不成功只能用爬虫方法进行get获取了
# 获取网页信息
import requests
url='https://cloud.tsinghua.edu.cn/d/fb9f16d6dc8f482596c2/files/?p=%2Fice_text.model&dl=1'
save_path='ice_text.model'
# 设置header
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
# 获取文件并写入
res = requests.get(url,headers=headers)
file1 =open(save_path,'wb')
file1.write(res.content)
file1.close()In [6]
# 这里因为解析出的下载的链接只在model-0000?这里有变化,只要在这个位置调整i就可以循环下载,保存文件名类似
url1='https://cloud.tsinghua.edu.cn/d/fb9f16d6dc8f482596c2/files/?p=%2Fpytorch_model-0000'
url2='-of-00008.bin&dl=1'
save_path1='pytorch_model-0000'
save_path2='-of-00008.bin'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
# 循环获取models,总共有8个基础模型
for i in range(8):
url=url1+str(i+1)+url2
save_path=save_path1+str(i+1)+save_path2
res = requests.get(url,headers=headers)
file1 =open(save_path,'wb')
file1.write(res.content)
file1.close()
print("第{}个模型下载已完成".format(i+1))第1个模型下载已完成 第2个模型下载已完成 第3个模型下载已完成 第4个模型下载已完成 第5个模型下载已完成 第6个模型下载已完成 第7个模型下载已完成 第8个模型下载已完成
2.5 对话脚本启动准备
做完以上步骤我们就可以去启动python脚本运行了,ChatGLM-6B下提供了cli_demo.py和web_demo.py两个文件来启动模型,第一个是使用命令行进行交互,第二个是使用gradio库使用本机服务器进行网页交互,这里只演示使用cli_demo.py脚本的启动
1.调整模型文件的启动路径
由于要使用本地模型启动,所以我们需要把从Hugging Face Hub加载改为本地路径加载,在/home/aistudio/work/ChatGLM-6B/下的cli_demo.py和web_demo.py文件中进行修改

修改后的地址

In [ ]
# 启动脚本测试,这里会报错是因为没有添加环境变量的原因
!python /home/aistudio/work/ChatGLM-6B/cli_demo.py2.添加环境变量
上面之所以会报错是是因为环境变量未添加

这里需要添加以下命令来解决问题
export LD_LIBRARY_PATH=(你的服务器环境路径):$LD_LIBRARY_PATH
如果是使用外部库
export LD_LIBRARY_PATH=(你的外部库环境路径):$LD_LIBRARY_PATH
In [12]
# 默认环境导入环境变量
!export LD_LIBRARY_PATH='/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/nvidia/cublas/lib:$LD_LIBRARY_PATH'In [1]
# 使用外部库环境导入环境变量
!export LD_LIBRARY_PATH="/home/aistudio/work/external-libraries/nvidia/cublas/lib:$LD_LIBRARY_PATH"3.项目启动
3.1 模型测试
完成以上操作我们就可以使用我们的模型测试了,打开命令行进行交互测试,请使用以下代码进行模型测试,目前使用一些小方法可实现正常对话,这里可能要多尝试几次(已经更新了cli_demo.py和web_demo.py可运行,推荐使用A100含以上的显卡)
解压启动文件到模型存放路径并启动
cd /home/aistudio/data/data203501
unzip chatglm-6b.zip
cd
python /home/aistudio/work/ChatGLM-6B/cli_demo.py
模型加载中

模型测试结果



3.2 项目总结
飞桨的paddle框架与torch框架会发生冲突,很容易就会因为框架冲突报错,这个我查了很多资料,用了很多办法但目前依然没有好的解决办法😅,由于时间问题后续可能不会再更新项目,只能等飞桨早日更新模型库加入新模型进来。不过整体流程是可在本地实现的,有兴趣和显卡算力的够可自己在本地搭建,这个项目在github上已经基于最开始的模型已经有了一定的优化,不用6G显存也可实现本地运行模型(我的2060还能打😂),其它详情方法请参考:https://github.com/THUDM/ChatGLM-6B ,以上就是部署的全流程了,希望本项目能对大家有帮助,希望大家能多多给💕
- 分析了ChatGLM模型文件的整体结构后,我对整体的模型运行逻辑进行了一个分析,后续如果有能力调整的可参考一下
models
——config.json # 模型的基本信息,包括运行时要调用的py文件和函数,模型的结构参数都放在该json
——configuration_chatglm.py # 设置模型的基本参数的py文件
——modeling_chatglm.py # 组网程序,也是模型主程序,后续调整环境需要对这个文件进行大幅调整
——quanitization.py # 量化程序,主要是为了调整Tensor的精度,默认是bfloat16
——tokenization_chatglm.py # 词嵌入程序,主要是为了将语句输入转化为词嵌入向量(token)形式,之后将其送进模型进行推理
——tokenizer_config.json # tokenizer的基本设置文件,可查看句子是通过何种方式进行向量化的
- 在尝试将torch转换paddle发现了挺多问题的,一是这个模型因为一些因素不能直接torch转paddle,我显存和内存都不够尝试Onxx转换也不行,二是模型权重torch的Tensor在转换为paddle的Tensor后直接加载模型后原本模型的一些类函数会失效,导致无法正常运行对话,三是模型组网程序是基于torch的,要转换成paddle后需要对其源文件进行大幅修改,这个工作十分复杂,且测试起来比较麻烦,目前我还无法完全解析
- 这个模型整体是基于torch环境搭建的,并且在运行预训练模型加载后,是调用hub远程代码进行组织本地代码加载的,其组网的modelling_chatglm文件整体均是使用torch环境,要想完全在paddle环境下运行需要对整体文件进行调整,这里我提供一些思路供大家参考1.先将模型的参数文件torch的Tensor转换为paddle的Tensor->修改modeling_chatglm.py中的torch代码转换成paddle的等效代码->调整config.json的启动文件2.将模型加载后使用pytorch2onxx进行转换->再使用onxx2paddle将onxx模型文件转换为paddle的

这个人很懒,什么都没有留下!
The Beatles – легендарная британская рок-группа, сформированная в 1960 году в Ливерпуле. Их музыка стала символом эпохи и оказала огромное влияние на мировую культуру. Среди их лучших песен: “Hey Jude”, “Let It Be”, “Yesterday”, “Come Together”, “Here Comes the Sun”, “A Day in the Life”, “Something”, “Eleanor Rigby” и многие другие. Их творчество отличается мелодичностью, глубиной текстов и экспериментами в звуке, что сделало их одной из самых влиятельных групп в истории музыки. Музыка 2024 года слушать онлайн и скачать бесплатно mp3.
这个人很懒,什么都没有留下!
Ace of Base — шведская поп-группа, образованная в 1990 году. Их музыкальный стиль сочетает в себе элементы поп-музыки, дэнса и электроники. Группа стала популярной благодаря хитам “All That She Wants”, “The Sign”, “Don’t Turn Around” и “Beautiful Life”. Эти композиции не только покорили чарты во многих странах мира, но и остаются классикой жанра до сих пор. Ace of Base оставили неизгладимый след в истории поп-музыки, их мелодии до сих пор радуют слушателей по всему миру. Скачать музыку 2024 года и слушать онлайн бесплатно mp3.